Schema Design Workshop
Gary J. Murakami, Ph.D.
10gen (the MongoDB company)
@GaryMurakami
users
usernamefirst_namelast_name
←
books
titleisbnlanguagecreated_byauthor
→
authors
first_namelast_name
users
usernamefirst_namelast_name
←
books
titleisbnlanguagecreated_by
{
"mongodb" : "relational db",
"database" : "database",
"collection" : "table",
"document" : "row",
"field" : "column",
"index" : "index",
"sharding" : {
"shard" : "partition",
"shard key" : "partition key"
}
}{
"_id": int,
"first_name": string,
"last_name": string
}{
"_id": int,
"username": string,
"password": string
}{
"_id": int,
"title": string,
"slug": string,
"author": int,
"available": boolean,
"isbn": string,
"pages": int,
"publisher": {
"city": string,
"date": date,
"name": string
},
"subjects": [ string, string ],
"language": string,
"reviews": [
{ "user": int, "text": string },
{ "user": int, "text": string }
],
}> db.authors.findOne()
{
_id: 1,
first_name: "F. Scott",
last_name: "Fitzgerald"
}> db.users.findOne()
{
_id: 1,
username: "emily@10gen.com",
password: "slsjfk4odk84k209dlkdj90009283d"
}> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: 1,
available: true,
isbn: "9781857150193",
pages: 176,
publisher: {
name: "Everyman's Library",
date: ISODate("1991-09-19T00:00:00Z"),
city: "London"
},
subjects: ["Love stories", "1920s", "Jazz Age"],
language: "English",
reviews: [
{ user: 1, text: "One of the best…" },
{ user: 2, text: "It's hard to…" }
]
}> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: 1,
available: true,
isbn: "9781857150193",
pages: 176,
publisher: {
name: "Everyman's Library",
date: ISODate("1991-09-19T00:00:00Z"),
city: "London"
},
subjects: ["Love stories", "1920s", "Jazz Age"],
language: "English",
reviews: [
{ user: 1, text: "One of the best…" },
{ user: 2, text: "It's hard to…" }
]
}> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: 1,
available: true,
isbn: "9781857150193",
pages: 176,
publisher: {
publisher_name: "Everyman's Library",
date: ISODate("1991-09-19T00:00:00Z"),
publisher_city: "London"
},
subjects: ["Love stories", "1920s", "Jazz Age"],
language: "English",
reviews: [
{ user: 1, text: "One of the best…" },
{ user: 2, text: "It's hard to…" }
]
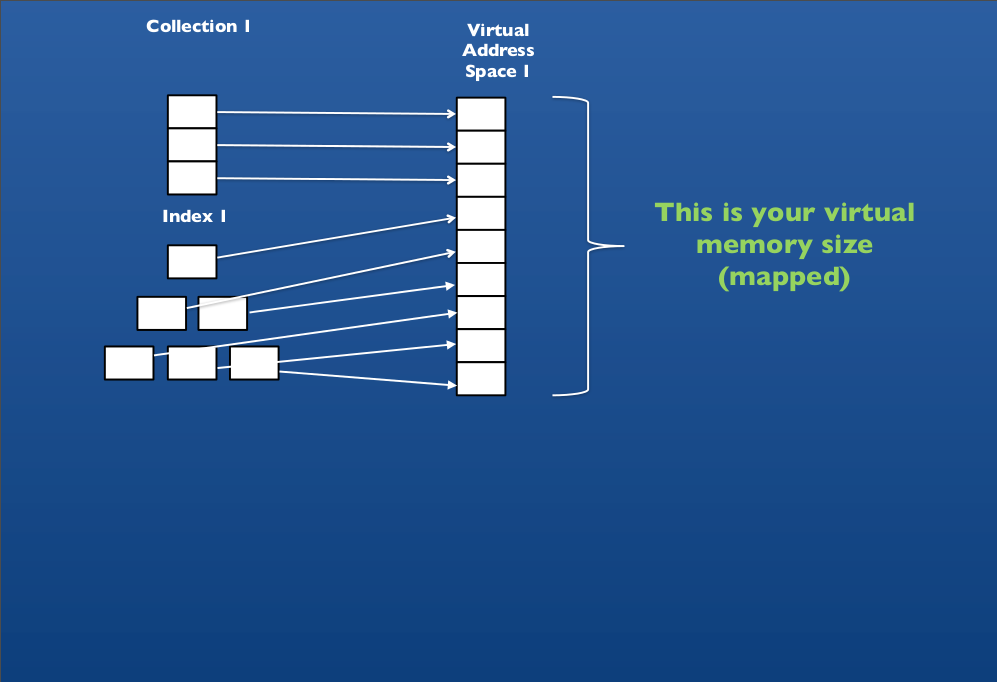
}
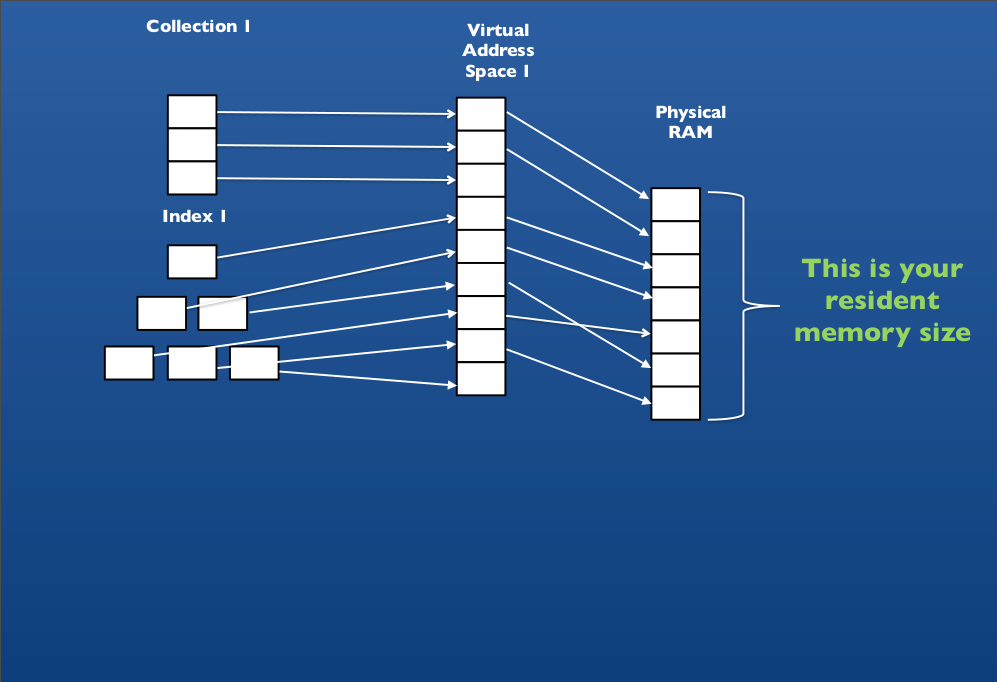
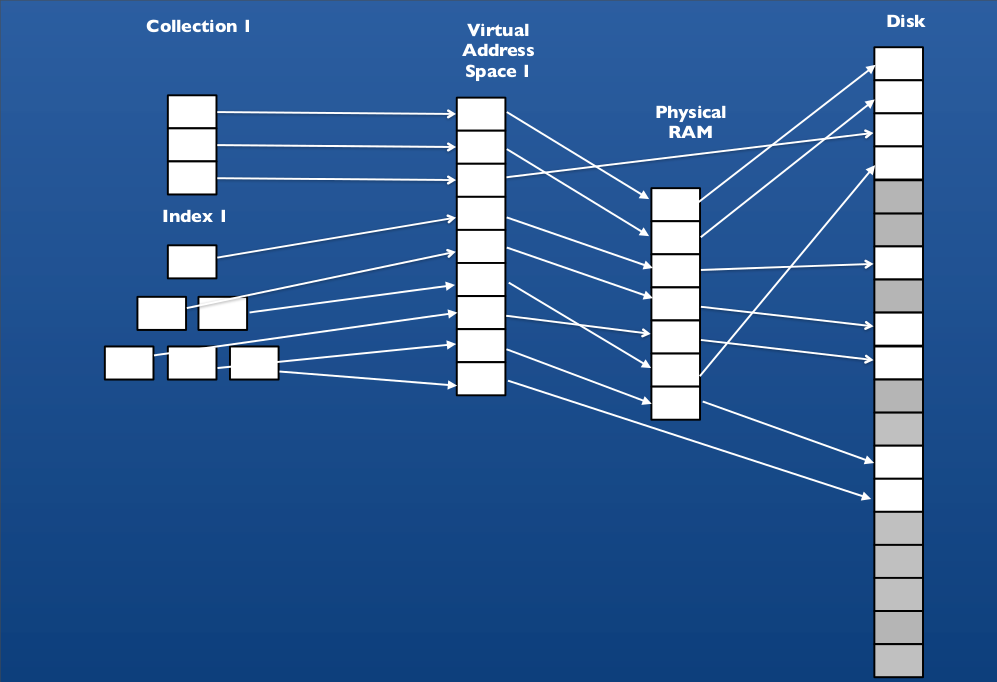
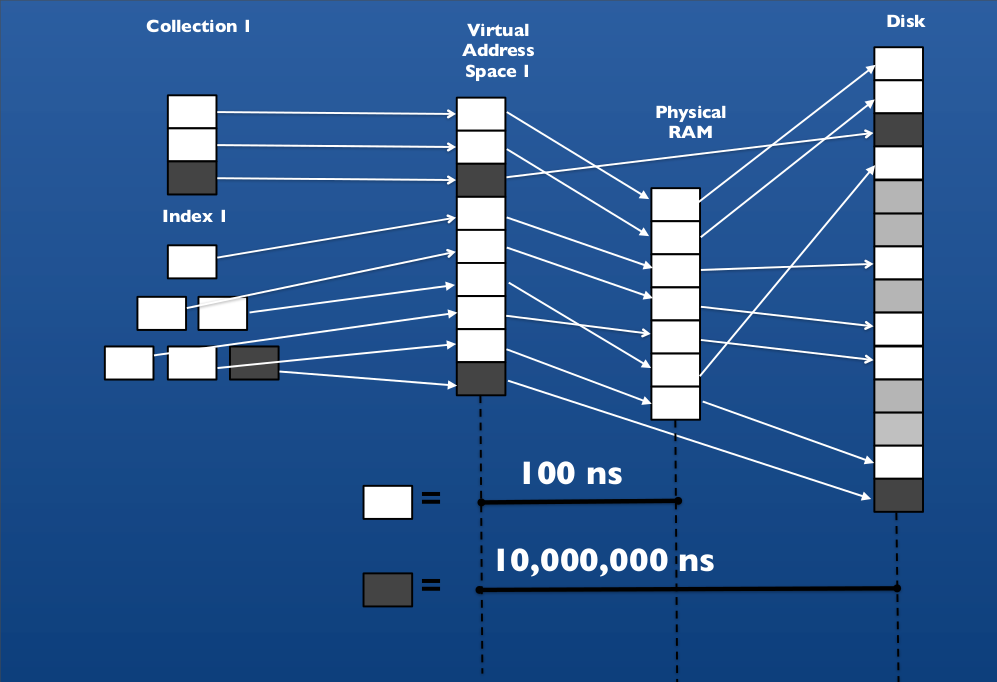
> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: 1,
available: true,
isbn: "9781857150193",
pages: 176,
publisher: {
name: "Everyman's Library",
date: ISODate("1991-09-19T00:00:00Z"),
city: "London"
},
subjects: ["Love stories", "1920s", "Jazz Age"],
language: "English",
reviews: [
{ user: 1, text: "One of the best…" },
{ user: 2, text: "It's hard to…" }
]
}> db.books.findOne()
{ _id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: 1,
available: true,
isbn: "9781857150193",
pages: 176,
publisher: {
name: "Everyman's Library",
date: ISODate("1991-09-19T00:00:00Z"),
city: "London"
},
subjects: ["Love stories", "1920s", "Jazz Age"],
language: "English",
reviews: [
{ user: 1, text: "One of the best…" },
{ user: 2, text: "It's hard to…" }
],
}// db.users (one document per user)
{ _id: ObjectId("…"),
username: "bob",
email: "bob@example.com"
}// db.reviews (one document per review)
{ _id: ObjectId("…"),
user: ObjectId("…"),
book: ObjectId("…"),
rating: 5,
text: "This book is excellent!",
created_at: ISODate("2012-10-10T21:14:07.096Z")
}// db.users (one document per user with all reviews)
{ _id: ObjectId("…"),
username: "bob",
email: "bob@example.com",
reviews: [
{ book: ObjectId("…"),
rating: 5,
text: "This book is excellent!",
created_at: ISODate("2012-10-10T21:14:07.096Z")
}
]
}// db.users (one document per user)
{ _id: ObjectId("…"),
username: "bob",
email: "bob@example.com"
}// db.books (one document per book with all reviews)
{ _id: ObjectId("…"),
// Other book fields…
reviews: [
{ user: ObjectId("…"),
rating: 5,
text: "This book is excellent!",
created_at: ISODate("2012-10-10T21:14:07.096Z")
}
]
}author = {
_id: 2,
first_name: "Arthur",
last_name: "Miller"
};
db.authors.insert(author);> db.authors.find({ "last_name": "Miller" })
{
_id: 2,
first_name: "Arthur",
last_name: "Miller"
}> db.books.ensureIndex({ "slug": 1 })
> db.books.find({ "slug": "the-great-gatsby" }).explain()
{
"cursor": "BtreeCursor slug_1",
"isMultiKey" : false,
"n" : 1,
"nscannedObjects" : 1,
"nscanned" : 1,
"scanAndOrder" : false,
"indexOnly" : false,
"nYields" : 0,
"nChunkSkips" : 0,
"millis" : 0,
// Other fields follow…
}> db.books.ensureIndex({ "subjects": 1 })> db.books.ensureIndex({ "publisher.name": 1 })review = {
user: 1,
text: "I did NOT like this book."
};
db.books.update(
{ _id: 1 },
{ $push: { reviews: review }}
);> db.books.remove({ _id: 1 })authors = db.authors.find({ first_name: /^f.*/i }, { _id: 1 });
authorIds = authors.map(function(x) { return x._id; });
db.books.find({author: { $in: authorIds }});> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
author: {
first_name: "F. Scott",
last_name: "Fitzgerald"
}
// Other fields follow…
}> db.books.find({ author.first_name: /^f.*/i })review = {
user: 1,
text: "I thought this book was great!",
rating: 5
};
> db.books.update(
{ _id: 3 },
{ $push: { reviews: review }}
);// db.reviews (one document per user per month)
{ _id: "bob-201210",
reviews: [
{ _id: ObjectId("…"),
rating: 5,
text: "This book is excellent!",
created_at: ISODate("2012-10-10T21:14:07.096Z")
},
{ _id: ObjectId("…"),
rating: 2,
text: "I didn't really enjoy this book.",
created_at: ISODate("2012-10-11T20:12:50.594Z")
}
]
}myReview = {
_id: ObjectId("…"),
rating: 3,
text: "An average read.",
created_at: ISODate("2012-10-13T12:26:11.502Z")
};
> db.reviews.update(
{ _id: "bob-201210" },
{ $push: { reviews: myReview }}
);cursor = db.reviews.find(
{ _id: /^bob-/ },
{ reviews: { $slice: 10 }}
).sort({ _id: -1 });
num = 0;
while (cursor.hasNext() && num < 10) {
doc = cursor.next();
for (var i = 0; i < doc.reviews.length && num < 10; ++i, ++num) {
printjson(doc.reviews[i]);
}
}cursor = db.reviews.update(
{ _id: "bob-201210" },
{ $pull: { reviews: { _id: ObjectId("…") }}}
);> db.subjects.findOne()
{
_id: 1,
name: "American Literature",
sub_category: {
name: "1920s",
sub_category: { name: "Jazz Age" }
}
}> db.subjects.find()
{ _id: "American Literature" }
{ _id : "1920s",
ancestors: ["American Literature"],
parent: "American Literature"
}
{ _id: "Jazz Age",
ancestors: ["American Literature", "1920s"],
parent: "1920s"
}
{ _id: "Jazz Age in New York",
ancestors: ["American Literature", "1920s", "Jazz Age"],
parent: "Jazz Age"
}> db.subjects.find({ ancestors: "1920s" })
{
_id: "Jazz Age",
ancestors: ["American Literature", "1920s"],
parent: "1920s"
}
{
_id: "Jazz Age in New York",
ancestors: ["American Literature", "1920s", "Jazz Age"],
parent: "Jazz Age"
}// Create a new loan request
db.loans.insert({
_id: { borrower: "bob", book: ObjectId("…") },
pending: false,
approved: false,
priority: 1,
});
// Find the highest priority request and mark as pending approval
request = db.loans.findAndModify({
query: { pending: false },
sort: { priority: -1 },
update: { $set: { pending: true, started: new ISODate() }},
new: true
});{
_id: { borrower: "bob", book: ObjectId("…") },
pending: true,
approved: false,
priority: 1,
started: ISODate("2012-10-11T22:09:42.542Z")
}// Library approves the loan request
db.loans.update(
{ _id: { borrower: "bob", book: ObjectId("…") }},
{ $set: { pending: false, approved: true }}
);// Request times out after seven days
limit = new Date();
limit.setDate(limit.getDate() - 7);
db.loans.update(
{ pending: true, started: { $lt: limit }},
{ $set: { pending: false, approved: false }}
);// db.recommendations (one document per user per book)
db.recommendations.insert({
book: ObjectId("…"),
user: ObjectId("…")
});
// Unique index ensures users can't recommend twice
db.recommendations.ensureIndex(
{ book: 1, user: 1 },
{ unique: true }
);
// Count the number of recommendations for a book
db.recommendations.count({ book: ObjectId("…") });db.books.update(
{ _id: ObjectId("…") },
{ $inc: { recommendations: 1 }}
});> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: 1,
// Other fields follow…
}
> db.authors.findOne({ _id: 1 })
{
_id: 1,
first_name: "F. Scott",
last_name: "Fitzgerald"
book: 1,
}> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: {
first_name: "F. Scott",
last_name: "Fitzgerald"
}
// Other fields follow…
}> db.authors.findOne()
{
_id: 1,
first_name: "F. Scott",
last_name: "Fitzgerald",
books: [1, 3, 20]
}> db.books.find({ author: 1 })
{
_id: 1,
title: "The Great Gatsby",
slug: "9781857150193-the-great-gatsby",
author: 1,
// Other fields follow…
}
{
_id: 3,
title: "This Side of Paradise",
slug: "9780679447238-this-side-of-paradise",
author: 1,
// Other fields follow…
}> db.authors.findOne()
{
_id: 1,
first_name: "F. Scott",
last_name: "Fitzgerald",
books: [
{ _id: 1, title: "The Great Gatsby" },
{ _id: 3, title: "This Side of Paradise" }
]
// Other fields follow…
}> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
authors: [1, 5]
// Other fields follow…
}> db.authors.findOne()
{
_id: 1,
first_name: "F. Scott",
last_name: "Fitzgerald",
books: [1, 3, 20]
}db.books.find({ authors: 1 });db.authors.find({ books: 1 });> db.books.findOne()
{
_id: 1,
title: "The Great Gatsby",
authors: [1, 5]
// Other fields follow…
}> db.authors.find({ _id: { $in: [1, 5] }})
{
_id: 1,
first_name: "F. Scott",
last_name: "Fitzgerald"
}
{
_id: 5,
first_name: "Unknown",
last_name: "Co-author"
}db.books.find({ authors: 1 });book = db.books.findOne(
{ title: "The Great Gatsby" },
{ authors: 1 }
);
db.authors.find({ _id: { $in: book.authors }});// db.rec_ts (time series buckets, hour and minute sub-docs)
db.rec_ts.insert({
book: ObjectId("…"),
day: ISODate("2012-10-11T00:00:00.000Z")
total: 0,
hour: { "0": 0, "1": 0, /* … */ "23": 0 },
minute: { "0": 0, "1": 0, /* … */ "1439": 0 }
});
// Record a recommendation created one minute before midnight
db.rec_ts.update(
{ book: ObjectId("…"), day: ISODate("2012-10-11T00:00:00.000Z") },
{ $inc: { total: 1, "hour.23": 1, "minute.1439": 1 }}
});
minute
[0] [1] … [1439]
hour0
[0] [1] … [59]
…
hour23
[1380] … [1439]
// db.rec_ts (time series buckets, each hour a sub-doc)
db.rec_ts.insert({
book: ObjectId("…"),
day: ISODate("2012-10-11T00:00:00.000Z")
total: 148,
hour: {
"0": { total: 7, "0": 0, /* … */ "59": 2 },
"1": { total: 3, "60": 1, /* … */ "119": 0 },
// Other hours…
"23": { total: 12, "1380": 0, /* … */ "1439": 3 }
}
});
// Record a recommendation created one minute before midnight
db.rec_ts.update(
{ book: ObjectId("…"), day: ISODate("2012-10-11T00:00:00.000Z") },
{ $inc: { total: 1, "hour.23.total": 1, "hour.23.1439": 1 }}
});> db.books.findOne()
{
_id: 47,
title: "The Wizard Chase",
type: "series",
series_title: "The Wizard's Trilogy",
volume: 2
// Other fields follow…
}db.books.find({ type: "series" });
db.books.find({ series_title: { $exists: true }});
db.books.find({ volume: { $gt: 0 }});db.books.ensureIndex({ series_title: 1 }, { sparse: true });
db.books.ensureIndex({ volume: 1 }, { sparse: true });// db.user_recs (track user's remaining and given recommendations)
db.user_recs.insert({
_id: "bob",
remaining: 8,
books: [3, 10]
});
// Record a recommendation if possible
db.user_recs.update(
{ _id: "bob", remaining: { $gt: 0 }, books: { $ne: 4 }},
{ $inc: { remaining: -1 }, $push: { books: 4 }}
});> db.user_recs.findOne()
{
_id: "bob",
remaining: 7,
books: [3, 10, 4]
}> db.book_refs.findOne()
{ book: 1,
referrers: [
{ domain: "google.com", count: 4 },
{ domain: "yahoo.com", count: 1 }
]
}db.book_refs.update(
{ book: 1, "referrers.domain": "google.com" },
{ $inc: { "referrers.$.count": 1 }}
);db.book_refs.update(
{ book: 1, "referrers.domain": "google.com" },
{ $inc: { "referrers.$.count": 1 }}
);> db.book_refs.findOne()
{ book: 1,
referrers: [
{ domain: "google.com", count: 5 },
{ domain: "yahoo.com", count: 1 }
]
}> db.book_refs.findOne()
{ book: 1,
referrers: {
"google_com": 5,
"yahoo_com": 1
}
}db.book_refs.update(
{ book: 1 },
{ $inc: { "referrers.bing_com": 1 }},
true
);db.runCommand({ addshard : "shard1.example.com" });
db.runCommand({ enableSharding: "library" });
db.runCommand({
shardCollection: "library.books",
key: { _id : 1}
});db.books.save({ _id: 35, title: "Call of the Wild" });
db.books.save({ _id: 40, title: "Tropic of Cancer" });
db.books.save({ _id: 45, title: "The Jungle" });
db.books.save({ _id: 50, title: "Of Mice and Men" });(−∞, +∞)
→
(−∞, 40)[40, +∞)
→
(−∞, 40)[40, 50)[50, +∞)
shard1
(−∞, 40)[40, 50)[50, 60)[60, +∞)
db.runCommand({ addshard : "shard2.example.com" });
shard1
(−∞, 40)[50, 60)
shard2
[40, 50)[60, +∞)
db.runCommand({ addshard : "shard3.example.com" });
shard1
(−∞, 40)
shard2
[40, 50)[60, +∞)
shard3
[50, 60)
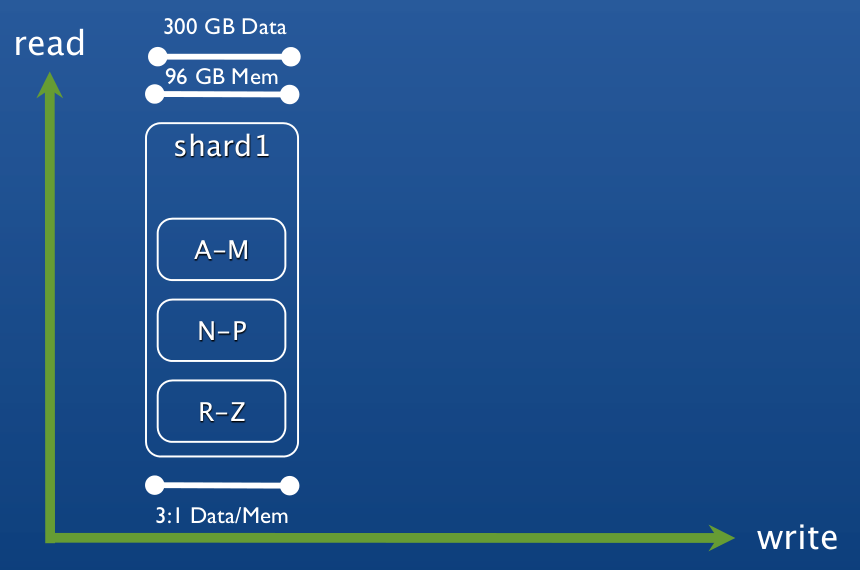
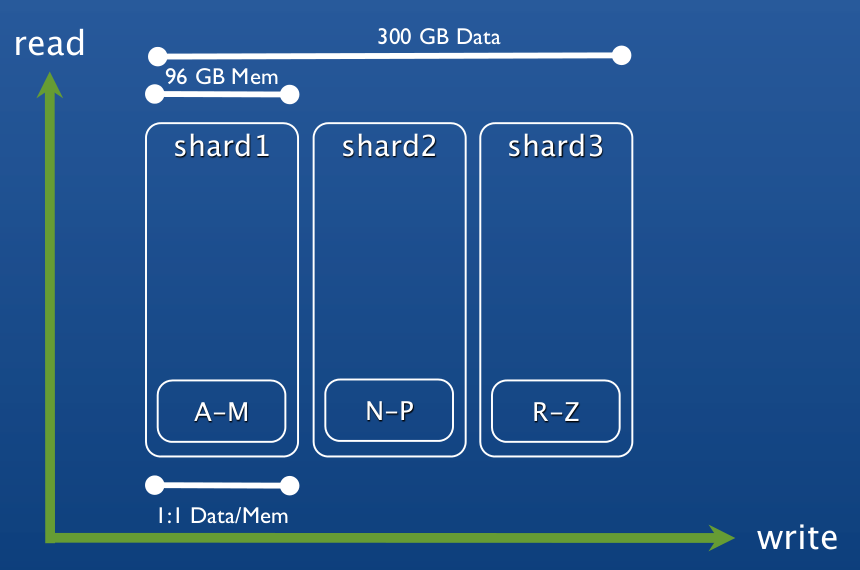
images
image_id: ???data: binary
The collection will be sharded by `image_id`. What should `image_id` be?
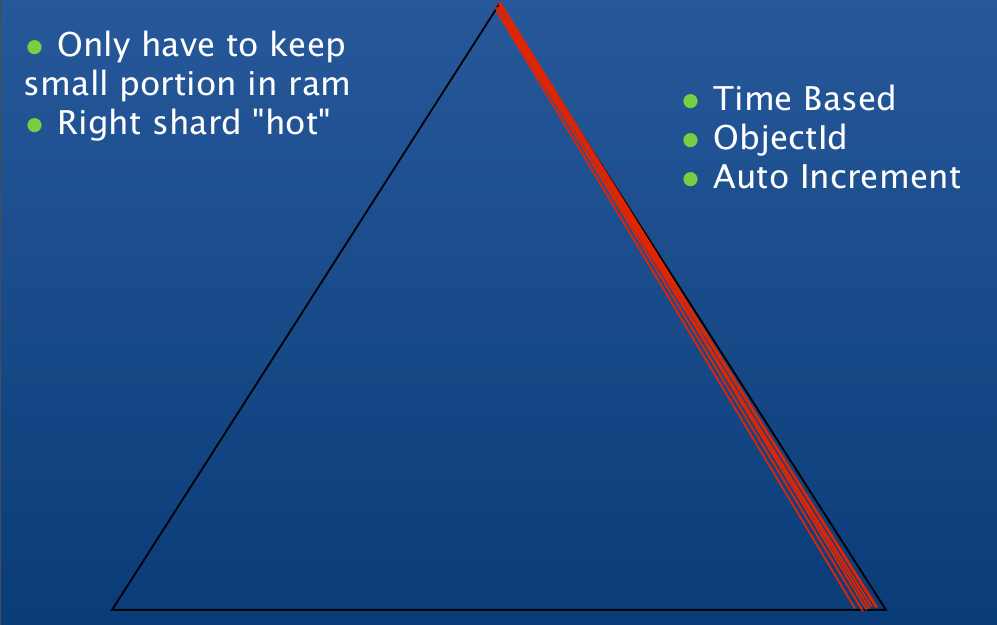 Right-balanced Access
Right-balanced Access
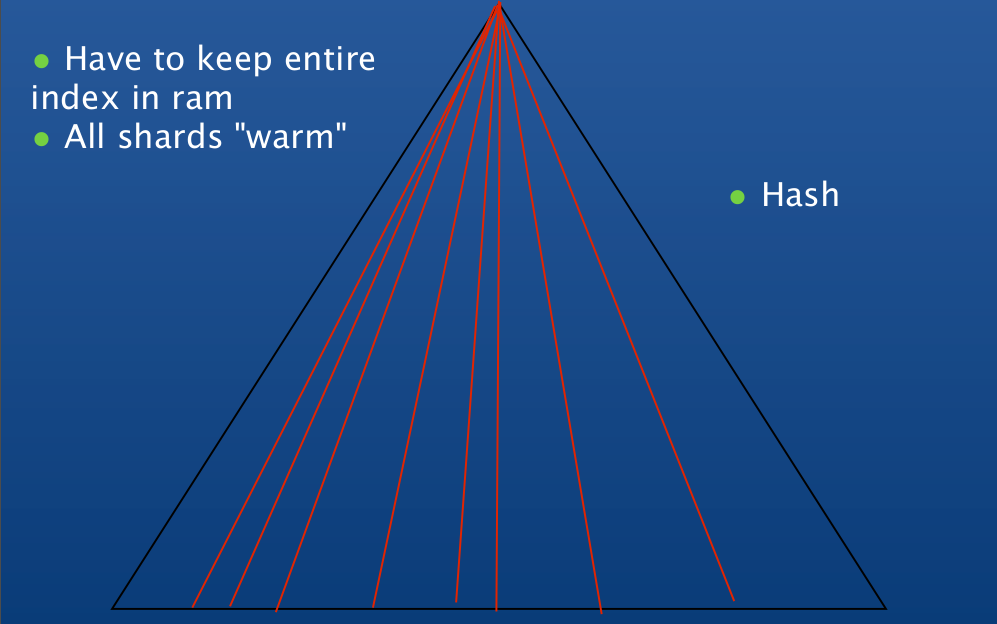 Random Access
Random Access
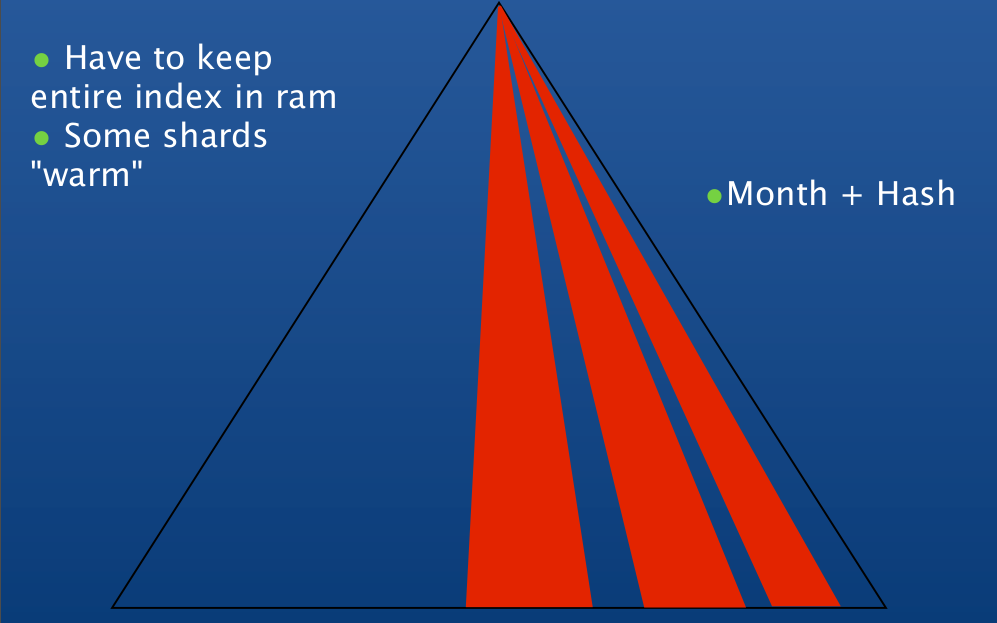 Segmented Access
Segmented Access
good principle of Don't Repeat Yourself (DRY) 2. Denormalization introduces redundancy
common practices such as caching for performance ### Consistency techniques * background or nightly process for eventual consistency * look-aside cache for immediate consistency, etc.